![[Oracle SQL] 함수와 문자 함수(LOWER(), UPPER(), INITCAP(), SUBSTR(), REPLACE(), CONCAT(), LENGTH(), INSTR(), LPAD(), RPAD(), LTRIM(), RTRIM())](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FcFcBJn%2FbtsAzcEbiyB%2FAAAAAAAAAAAAAAAAAAAAANT9Ce1WnWzymWy5uBj0yOkRwBLIZWL1U6BIQ101cD5h%2Fimg.jpg%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1782831599%26allow_ip%3D%26allow_referer%3D%26signature%3DtRTP7d%252B0xok5RMRxMc92ssTJbHE%253D)

본 게시글은 이수안컴퓨터연구소의 데이터베이스 유튜브 동영상을 개인적으로 정리하는 글입니다.
함수
함수
• 자주 사용되는 기능을 미리 만들어 놓고 필요할 때마다 사용하는개념
• DBMS에서는 주로 사용되는 문자, 숫자, 날짜 등의 다양한 기능과 데이터 타입을 변환하는 함수들을 제공
| 타입 | 데이터 타입 | 설명 |
| 문자 | CHAR(n) | n 크기의 고정 길이 문자 형식 저장 (최대 2,000 byte) |
| 문자 | VARCHAR2(n) | n 크기의 가변 길이 문자 형식 저장 (최대 4,000 byte) |
| 숫자 | NUMBER(p, s) | 숫자 형식 저장(p: 정수 자리수, s: 소수 자리수) |
| 날짜 | DATE | 날짜 형식 저장 (9999년 12월 31일까지 저장 가능) |
단일행 함수
• 데이터 값 계산 및 조작
• 행별로 하나의 결과를 반환
• SELECT, WHERE, ORDER BY 절에서 사용
• 중첩 함수로 사용 가능 (가장 안쪽 단계에서 바깥쪽 단계순으로 진행)
• 문자, 숫자, 날짜, 변환, 일반 함수 등이 존재
다중행 함수(그룹 함수, 집계 함수)
• 행의 그룹 계산 및 요약
• 여러 행이 입력되고, 결과는 하나의 행씩 반환
• GROUP BY, HAVING 절 사용

문자 함수
• 문자 함수는 주로 데이터 조작에 사용되며 문자와 문자열은 작은 따옴표(‘)로 묶어서 표현

LOWER(), UPPER(), INITCAP()
• 문자열을 소문자로 변환하는 LOWER() 함수, 문자열을 대문자로 변환하는 UPPER() 함수, 첫 문자만 대문자로 변환하는 INITCAP() 함수
--employees 테이블에서 first_name의 원래 그대로, 소문자, 대문자, 첫글자만 대문자를 출력
SELECT first_name, LOWER(first_name), UPPER(first_name), INITCAP(first_name) FROM employees;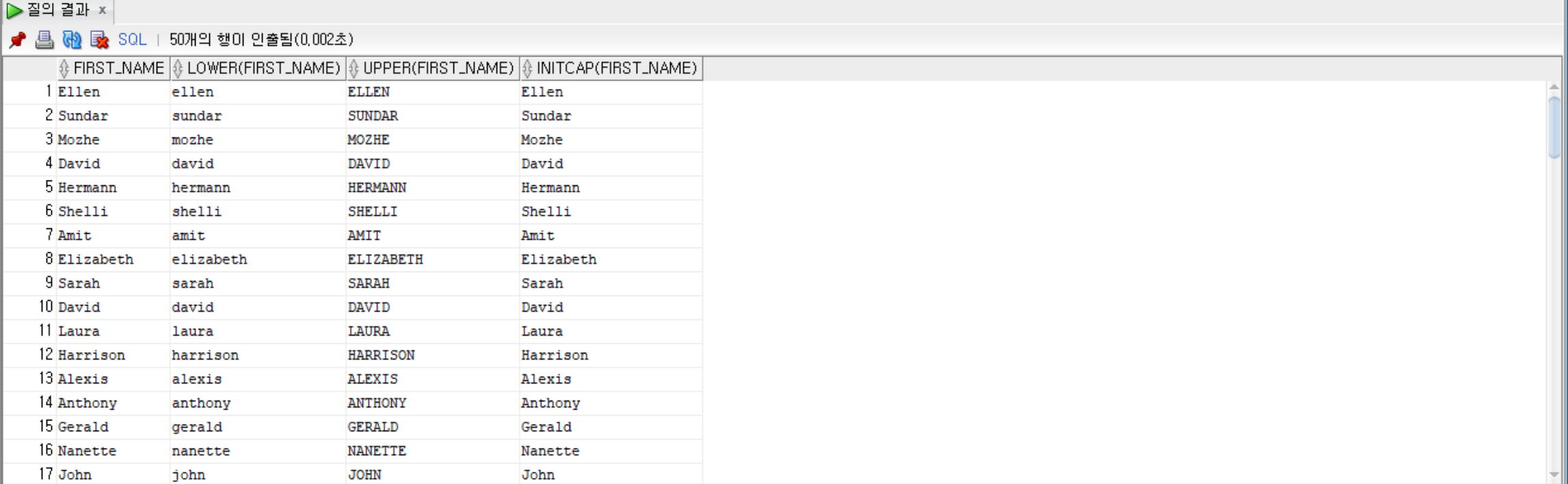
SUBSTR()
• 문자열에서 지정된 길이 만큼의 일부만 추출할 때 사용
--employees 테이블에서 job_id의 원래 그대로, 앞에서 두글자, 4번째 idx에서 끝까지 출력
SELECT job_id, SUBSTR(job_id, 1, 2), SUBSTR(job_id, 4) FROM employees;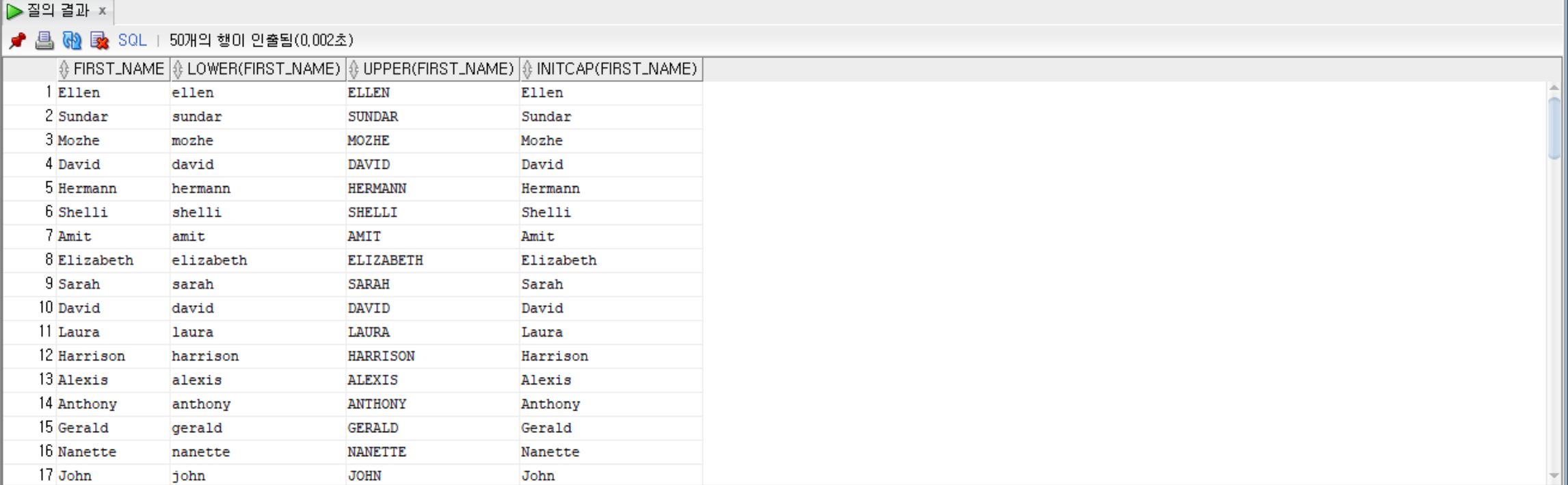
REPLACE()
• 특정 문자열을 찾아서 바꾸는 함수
--employees 테이블에서 job_id의 원래 그대로, job_id의 MGR을 MANAGER로 변경하여 출력
SELECT job_id, REPLACE(job_id, 'MGR', 'MANAGER') FROM employees;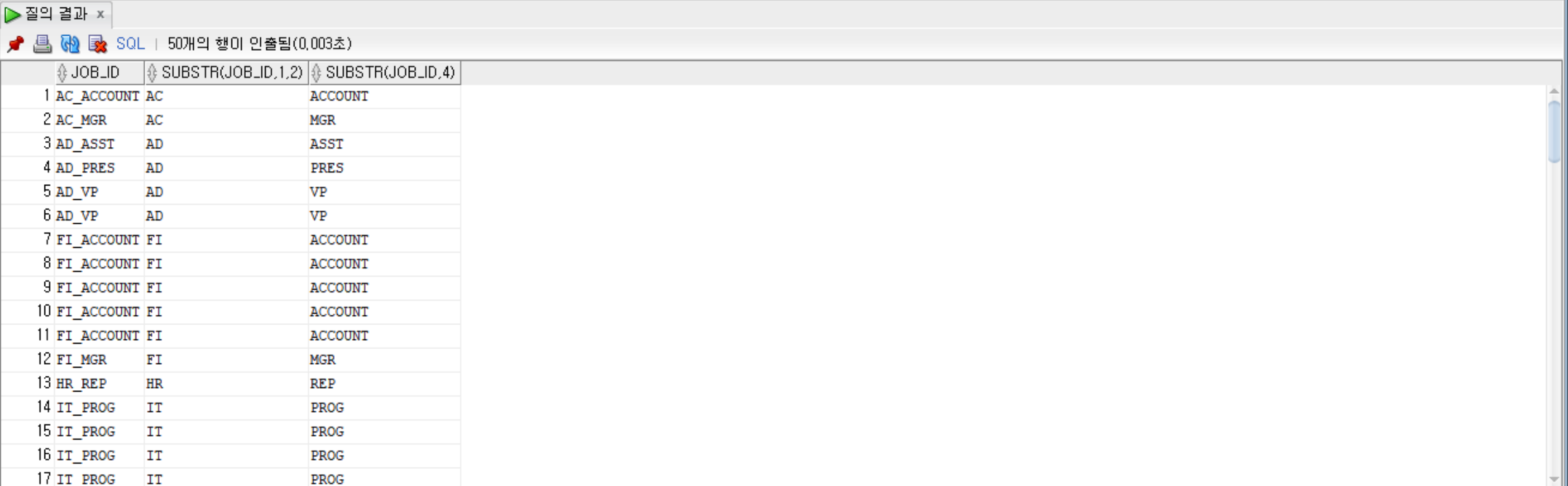
--employees 테이블에서 job_id의 원래 그대로, job_id의 PROG를 PROGRAMMER로 변경하여 출력
SELECT job_id, REPLACE(job_id, 'PROG', 'PROGRAMMER') FROM employees;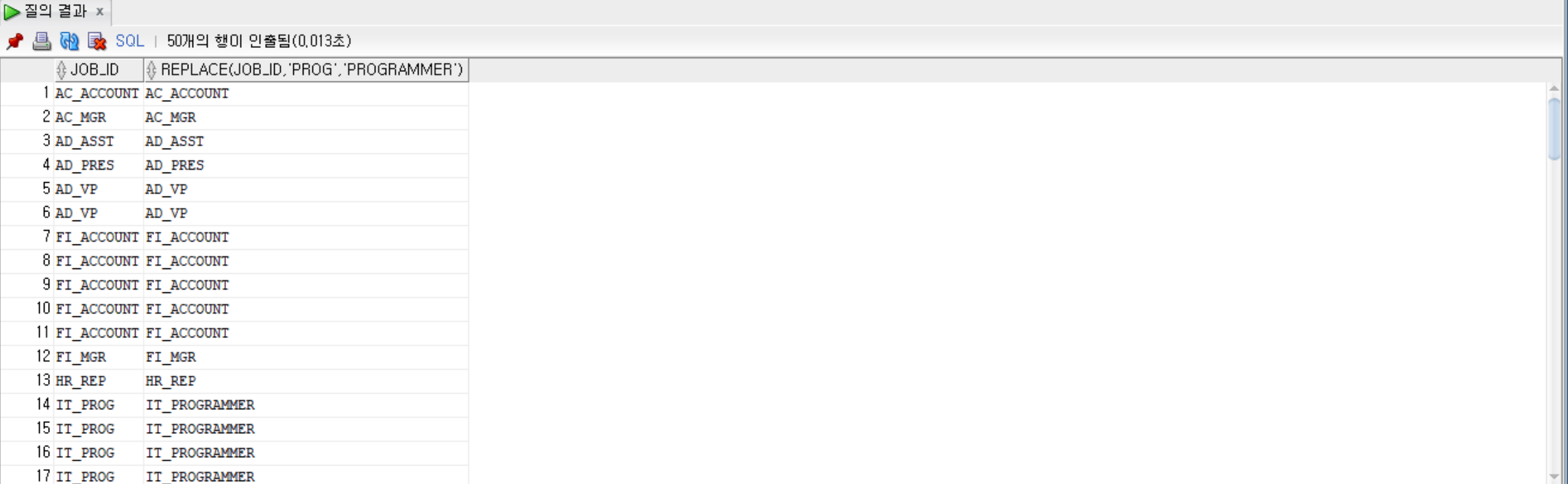
CONCAT()
• 두 개의 문자열을 하나로 합치는 함수
--employees 테이블에서 first_name을 ' '과 last_name을 합친 값을 출력
SELECT CONCAT(first_name, CONCAT(' ', last_name)) FROM employees;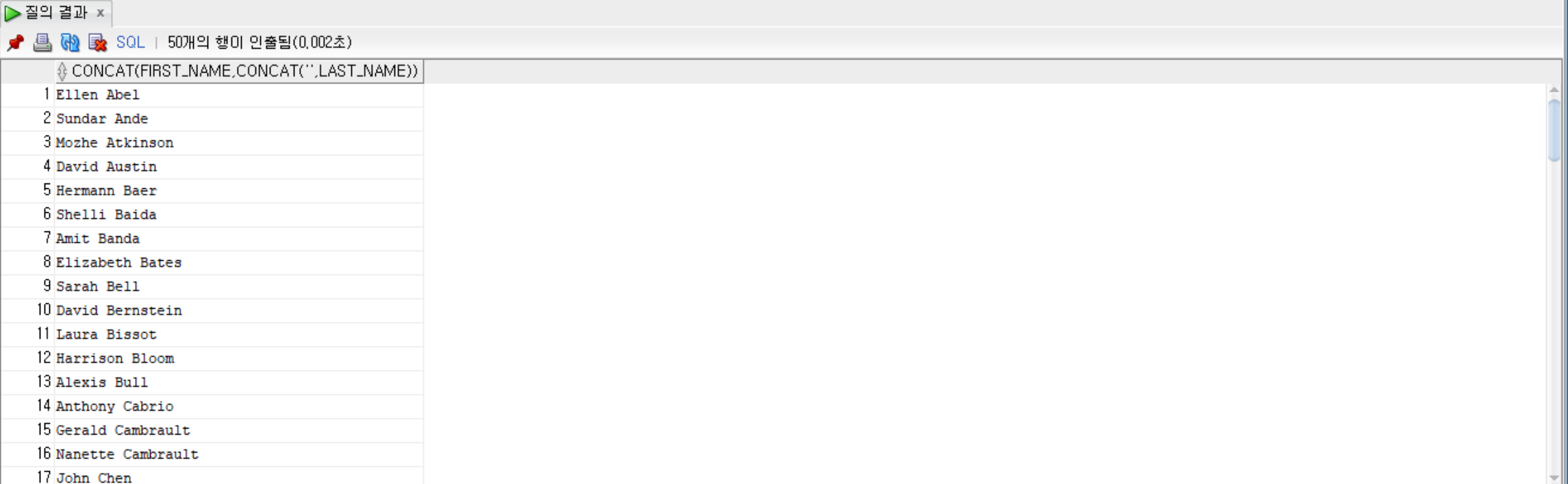
LENGTH()
• 문자열의 길이를 반환하는 함수
--employees 테이블에서 first_name, first_name의 길이를 출력
SELECT first_name, LENGTH(first_name) FROM employees;
INSTR()
• 문자열 위치값을 반환하는 함수
--employees 테이블에서 first_name, first_name에서 a가 있는 idx를 출력
SELECT first_name, INSTR(first_name, 'a') FROM employees;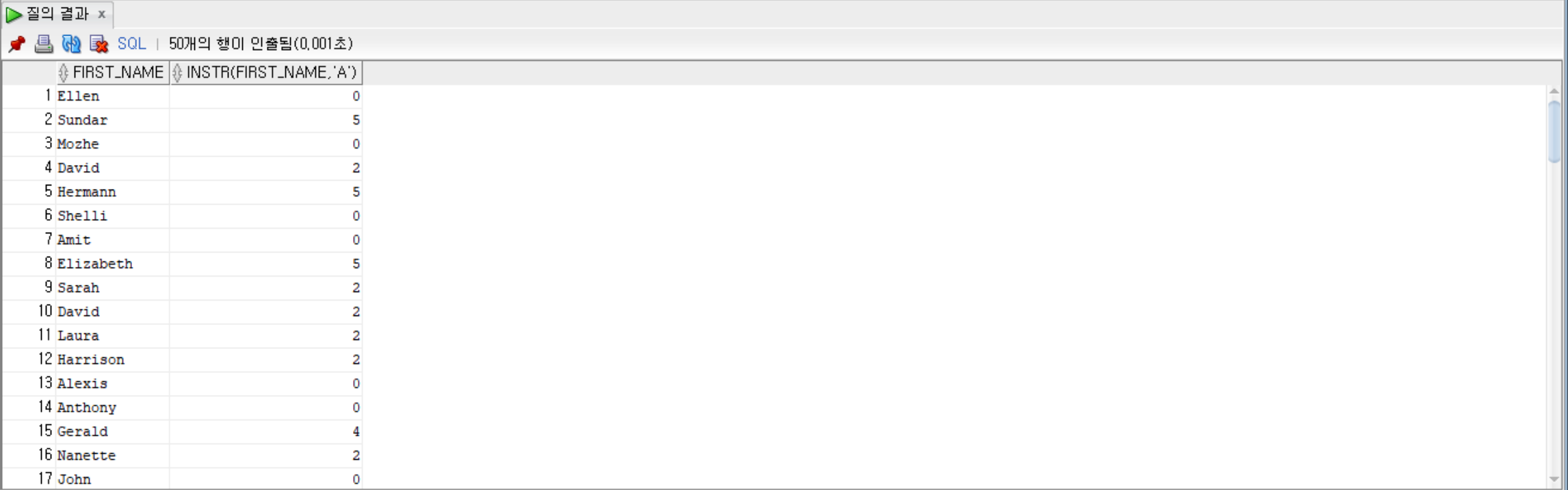
LPAD(), RPAD()
• 특정 문자를 왼쪽부터 채우는 LPAD() 함수, 특정 문자를 오른쪽부터 채우는 RPAD() 함수
--employees 테이블에서 총 10글자중 first_name을 오른쪽부터 채우고 남은 왼쪽은 *로 채움, 총 10글자중 first_name을 왼쪽부터 채우고 남은 오른쪽은 *로 채움
SELECT LPAD(first_name, 10, '*'), RPAD(first_name, 10, '*') FROM employees;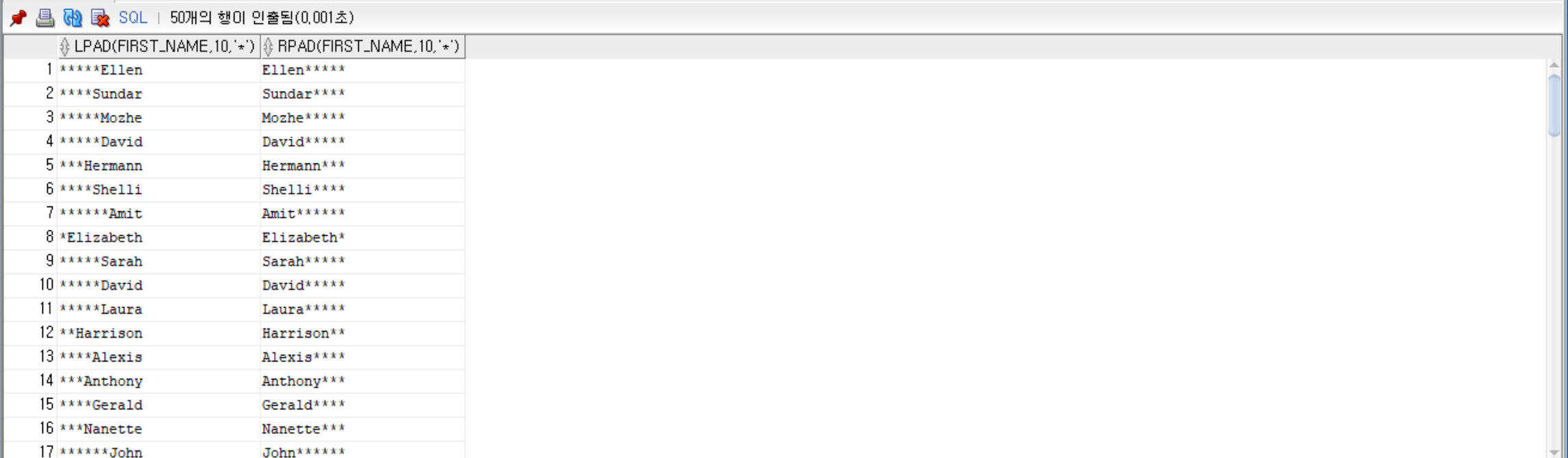
LTRIM(), RTRIM()
• 왼쪽에 특정 문자를 제거하는 LPAD() 함수, 오른쪽에 특정 문자를 제거하는 RPAD() 함수
--employees 테이블에서 job_id의 가장 왼쪽에 있는 A를 제거, job_id의 가장 오른쪽에 있는 T를 제거
SELECT job_id, LTRIM(job_id, 'A'), RTRIM(job_id, 'T') FROM employees;
TRIM()
• 문자열의 공백(space)을 제거하는데 사용하는 함수
--양쪽에 있는 공백 제거
SELECT TRIM(' Suan '), TRIM(' Su an') FROM dual;
DUAL 테이블
• 하나의 열 DUMMY와 하나의 값 ‘X’를 가지고 있는 테이블로 특정 테이블을 참조하지 않고 출력할 때 사용
--하나의 열 DUMMY와 하나의 값 ‘X’를 가지고 있는 테이블로 특정 테이블을 참조하지 않고 출력할 때 사용
SELECT * FROM dual;
연습 문제
--jobs 테이블에서 job_title과 소문자와 대문자로 변환한 job_title을 조회
SELECT job_title, LOWER(job_title) ,UPPER(job_title) FROM jobs;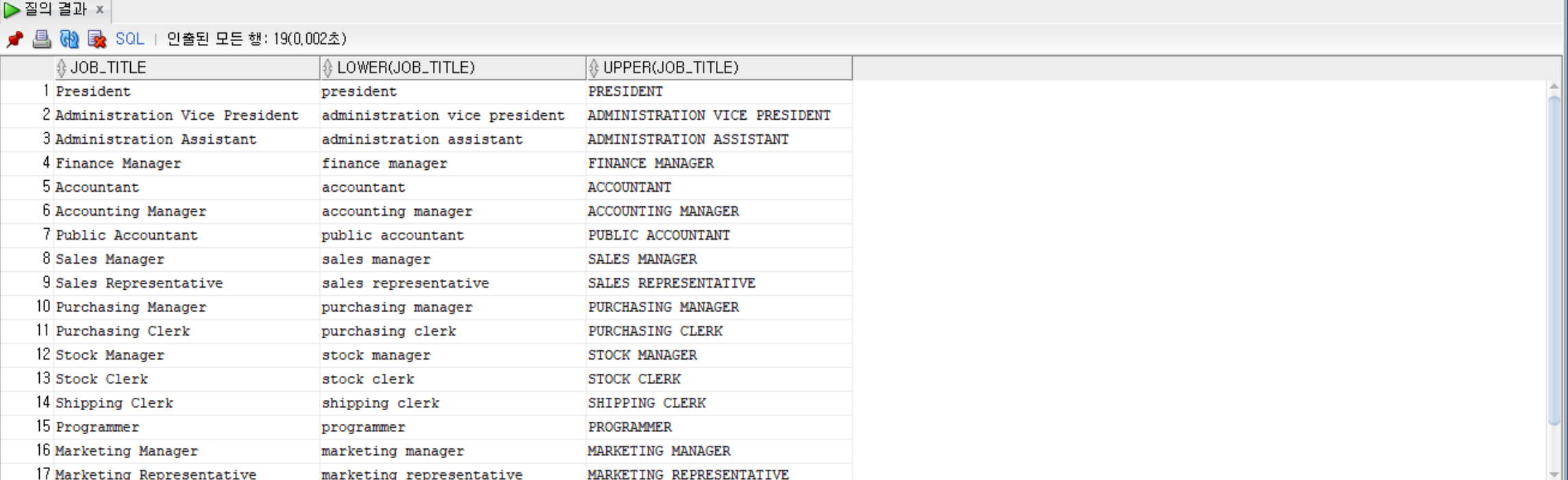
--employees 테이블에서 first_name 첫 1 문자와 last_name 조회
SELECT first_name, SUBSTR(first_name, 1,1) FROM employees;
--employees 테이블에서 job_id가 ‘REP’인 부분을 ‘REPRESENTATIVE’로 바꿔서 조회
SELECT job_id, REPLACE(job_id, 'REP', 'REPRESENTATIVE') FROM Employees;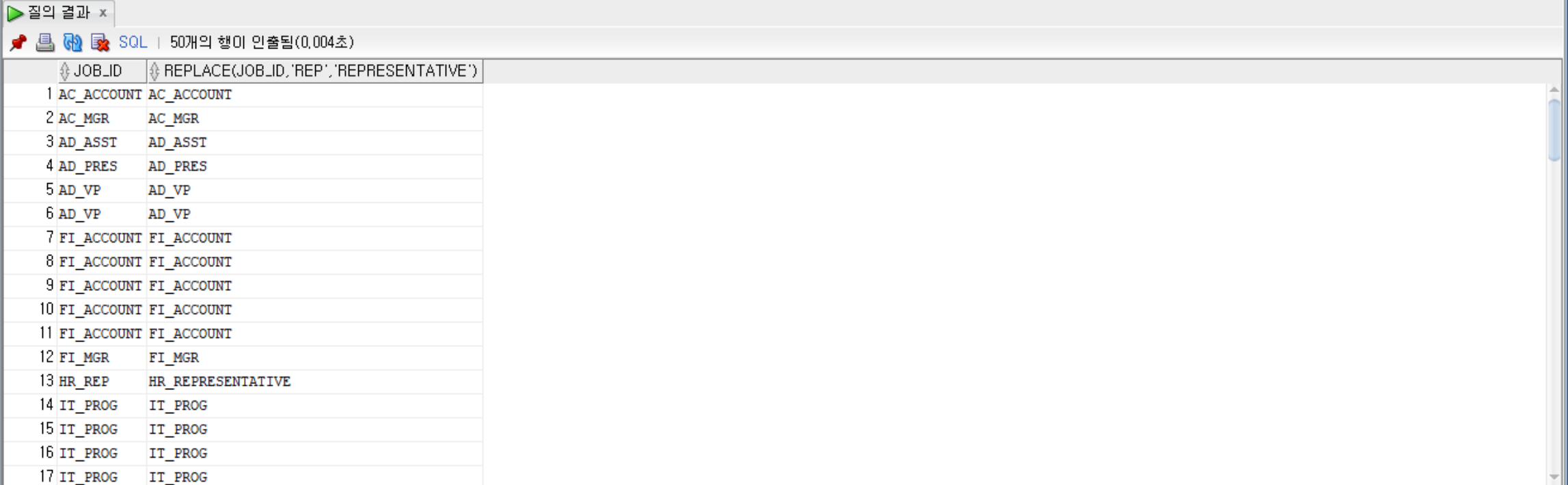
-- employees 테이블에서 first_name 첫 1 문자와 last_name을 중간에 공백을 두고 하나로 결합하여 조회
SELECT CONCAT(SUBSTR(first_name, 1, 1), CONCAT(' ', last_name)) from employees;
--employees 테이블에서 first_name과 last_name의 길이를 합쳐서 조회
SELECT LENGTH(CONCAT(first_name, last_name)) from employees;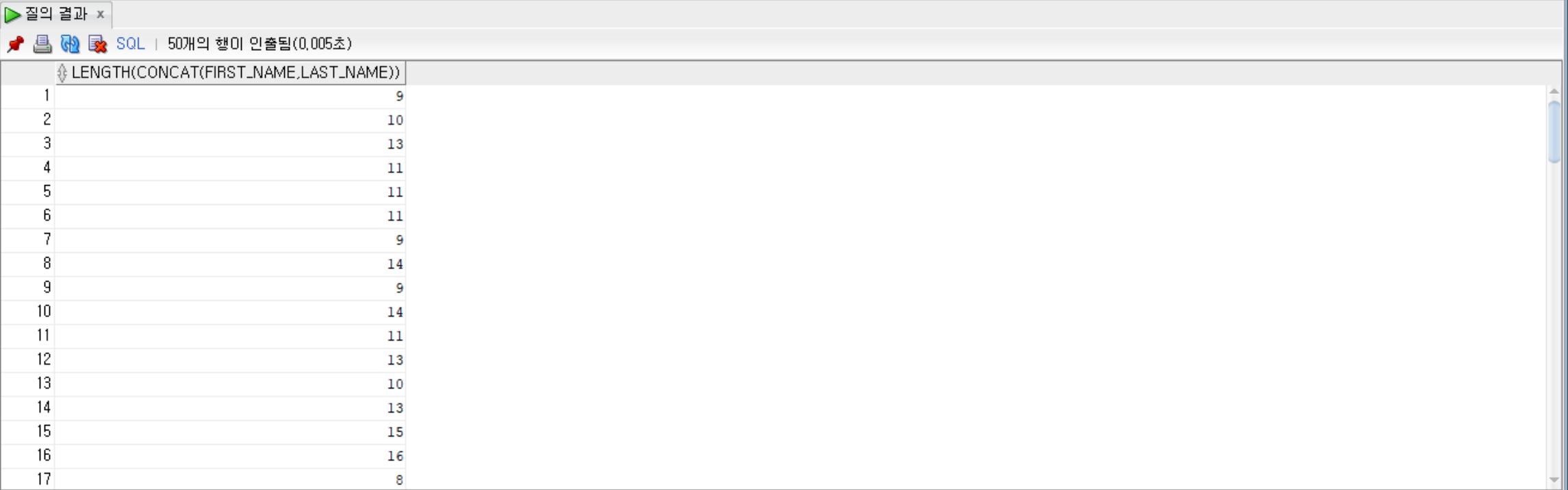
--employees 테이블에서 first_name과 last_name의 길이를 합쳐서 조회
SELECT LENGTH(first_name) + LENGTH(last_name) from employees;
--employees 테이블에서 job_id와 job_id에 ‘A’ 문자 위치 조회
SELECT job_id, INSTR(job_id, 'A') FROM employees;
--locations 테이블의 city를 15자리 문자열로 바꾸고, 빈 공간을 ‘.’으로 표현하여 조회
SELECT LPAD(city, 15, '.'), RPAD(city, 15, '.') FROM locations;
--locations 테이블에서 city의 왼쪽부터 ‘S’ 문자를 지운 것과 오른쪽부터 ‘e’ 문자를 지운 결과를 조회
SELECT LTRIM(city, 'S'), RTRIM(city, 'e') FROM locations;
'데이터베이스 > Oracle SQL' 카테고리의 다른 글
| [Oracle SQL] 집계 및 그룹 함수(COUNT(), SUM(), AVG(), MAX(), MIN(), GROUP BY, HAVING) (0) | 2023.11.22 |
|---|---|
| [Oracle SQL] 숫자, 날짜, 변환, 일반 함수 (1) | 2023.11.21 |
| [Oracle SQL] 정렬, 집합 연산(ORDER BY, UNION, UNION ALL, INTERSECT, MINUS)과 SQL연산자(BETWEEN, IN, IS NULL, LIKE) (0) | 2023.11.20 |
| [Oracle SQL] 조건 검색과 비교, 논리 연산(WHERE, AND, OR, NOT) (1) | 2023.11.20 |
| [Oracle SQL] SELECT 문 (1) | 2023.11.19 |
-
![[Oracle SQL] 집계 및 그룹 함수(COUNT(), SUM(), AVG(), MAX(), MIN(), GROUP BY, HAVING)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2Fb67h0I%2FbtsAy9n5JKA%2FAAAAAAAAAAAAAAAAAAAAACDKsTSPDjYwXa8qP6rlZHudwnrx95Fq_PPjQAosC6A-%2Fimg.jpg%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1782831599%26allow_ip%3D%26allow_referer%3D%26signature%3DWVTmmP3VB7g3bQHh%252BGCvuiJveDQ%253D) [Oracle SQL] 집계 및 그룹 함수(COUNT(), SUM(), AVG(), MAX(), MIN(), GROUP BY, HAVING)2023.11.22
[Oracle SQL] 집계 및 그룹 함수(COUNT(), SUM(), AVG(), MAX(), MIN(), GROUP BY, HAVING)2023.11.22 -
![[Oracle SQL] 숫자, 날짜, 변환, 일반 함수](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FcMaOaj%2FbtsAyWbJGNx%2FAAAAAAAAAAAAAAAAAAAAAKXqu5zoI0ct1ccIB_H4awPRw4jKsHnJMCZP9tYrhFxw%2Fimg.jpg%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1782831599%26allow_ip%3D%26allow_referer%3D%26signature%3D2ayWYyCRUc1iTstz7ObG6Ww5E2o%253D) [Oracle SQL] 숫자, 날짜, 변환, 일반 함수2023.11.21
[Oracle SQL] 숫자, 날짜, 변환, 일반 함수2023.11.21 -
![[Oracle SQL] 정렬, 집합 연산(ORDER BY, UNION, UNION ALL, INTERSECT, MINUS)과 SQL연산자(BETWEEN, IN, IS NULL, LIKE)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FcFfxpw%2FbtsAw9amv8U%2FAAAAAAAAAAAAAAAAAAAAAMm3tESN4pVJAhuCZAU17YaPpwT7uJCU19UNl2oTdDOr%2Fimg.jpg%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1782831599%26allow_ip%3D%26allow_referer%3D%26signature%3DRCHsdeKOOg8F%252BluU9HRrwgISF%252Fk%253D) [Oracle SQL] 정렬, 집합 연산(ORDER BY, UNION, UNION ALL, INTERSECT, MINUS)과 SQL연산자(BETWEEN, IN, IS NULL, LIKE)2023.11.20
[Oracle SQL] 정렬, 집합 연산(ORDER BY, UNION, UNION ALL, INTERSECT, MINUS)과 SQL연산자(BETWEEN, IN, IS NULL, LIKE)2023.11.20 -
![[Oracle SQL] 조건 검색과 비교, 논리 연산(WHERE, AND, OR, NOT)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FJzgGG%2FbtsAyJWDYLE%2FAAAAAAAAAAAAAAAAAAAAAJq6BN0MUR7i0glxEe-PEFNo9NJW7nRkbrMMblwENdux%2Fimg.jpg%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1782831599%26allow_ip%3D%26allow_referer%3D%26signature%3DI%252FnN4vwvACGXBfaDE2T2bB08Dy8%253D) [Oracle SQL] 조건 검색과 비교, 논리 연산(WHERE, AND, OR, NOT)2023.11.20
[Oracle SQL] 조건 검색과 비교, 논리 연산(WHERE, AND, OR, NOT)2023.11.20